La información que los organismos policiales almacenan sobre detenciones o incidentes delictivos, así como los avisos a los departamentos de policía, tienen un valor enorme para resolver futuros casos que se pueden plantear.
Analizar manualmente esta gran cantidad de datos en busca de patrones puede llevar mucho tiempo y sus resultados pueden ser limitados. Nos propusimos demostrar cómo pueden ayudar los métodos más avanzados de análisis de textos a mejorar los resultados. En concreto, queríamos descubrir patrones textuales y geoespaciales procesables relacionados con la lucha contra la trata de seres humanos (Figura 1) y otros delitos.

Para ello, teníamos que pensar en cómo mejorar el proceso con la tecnología. En concreto, se trataba de proporcionar capacidades de las que se beneficiarían las personas que trabajan día a día en la policía, en lugar de un analista o un científico de datos. En última instancia, lo que pretendíamos era mejorar la efectividad de los investigadores policiales mediante el uso de análisis de textos para poner de relieve incidentes relacionados con el tráfico de personas y otros patrones delictivos, proporcionando a continuación un acceso intuitivo a los mismos a través de informes visuales. Afortunadamente, los métodos de análisis de textos que hemos aplicado en otros proyectos y que categorizan automáticamente los datos y buscan tendencias, entidades (personas, lugares, objetos) y conexiones entre ellas, funcionan muy bien en la documentación policial.
Este flujo de trabajo y enfoque puede verse en la Figura 2, que detalla el proceso y el análisis aplicado a la información policial. Los documentos de texto policiales se procesaron en los flujos visuales de análisis de texto de la interfaz gráfica y asistida, donde se aplicó el procesamiento del lenguaje natural y las técnicas de análisis de texto predefinas que incluye la solución de SAS, como análisis de temas, extracción de entidades, clasificación, perfilado de los datos de texto y más. Este enfoque basado en flujos visuales dio como resultado tablas estandarizadas y listas para el análisis en Visual Analytics con el objetivo de explorar, investigar y visualizar los resultados de nuestro análisis. Este proceso proporcionó un enorme acelerador de tiempo a resultados en términos de extracción de información relevante que sería de utilidad inmediata para los investigadores policiales. En este proceso identificamos patrones de robo, violencia y trata de seres humanos en cuestión de minutos a partir de las 45.000 filas de datos de las que se disponía.

Gran parte de nuestros resultados se basaron en reglas que desarrollamos utilizando SAS Visual Text Analytics (VTA), esencialmente identificando estos patrones delictivos mencionados anteriormente. Se utilizó un conjunto de reglas conceptuales e integración de código abierto para extraer, geocodificar y categorizar las ubicaciones por tipo. Para ello, se escribió una regla que extraía las direcciones de las calles. Esta regla utilizaba una combinación de números de calle, palabras de calle (Avenue, Street, Drive, etc.), indicadores de dirección (N, S, E, W) y palabras de relleno que representaban el nombre literal de la calle. De este modo, pudimos filtrar los incidentes ocurridos junto a centros escolares, como se muestra en la figura 3.
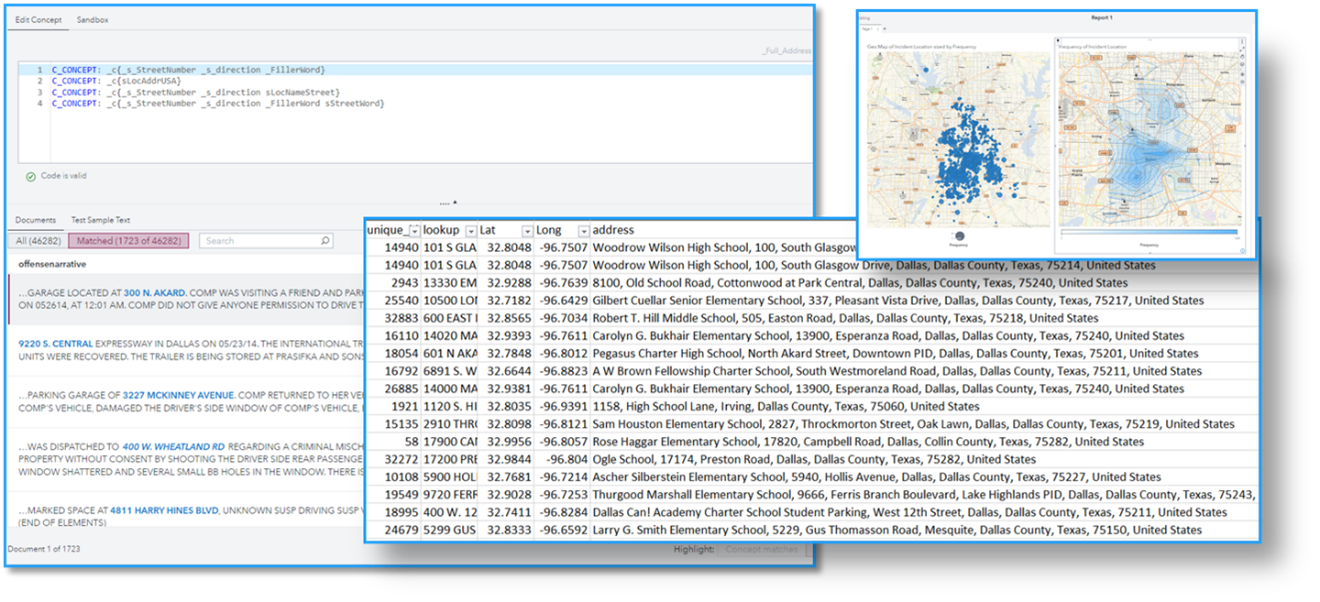
Tras extraer los nombres completos de las calles, se pasaron por un proceso de Python (utilizando geopy) que produjo una latitud y una longitud para cada dirección. Las coordenadas resultantes se geocodificaron a la inversa. Esto se hizo para recuperar la dirección a partir de las coordenadas recién descubiertas y obtener una dirección más detallada.
Ejemplo de geocodificación y geocodificación inversa de direcciones:
- Nombre original de la calle: 920 SAS Campus Drive Cary, NC 27513
- Geocoordenadas: 35.815658, -78.749284
- Geo codificación inversa: SAS Global Education Center, 920 SAS Campus Drive Cary, NC 27513
Como se ha visto en el ejemplo anterior, al realizar la geo codificación inversa se puede obtener información adicional como el hotel, la gasolinera, el colegio u otros nombres clave de esta dirección. Esta información adicional nos permitió agrupar los lugares extraídos en una taxonomía creada por VTA que clasificaba los lugares por tipo. Para este proyecto creamos unas 10 tipologías de ubicación, que incluían gasolineras, restaurantes, hoteles y colegios, entre otros. Cuando se combina con análisis adicionales, esta categorización adicional es útil y proporciona nuevos campos estructurados para actuar como puntos de entrada para el análisis con Visual Analytics. Este punto de entrada adicional permite el análisis exploratorio y el descubrimiento rápido de hechos relevantes e interesantes. Un ejemplo es la localización de un robo con arma de fuego ocurrido frente a una escuela primaria. Pudimos geolocalizar y clasificar la información no estructurada en función de la hora, el lugar y el tipo de suceso mediante la geo codificación, la evaluación del tipo de ubicación y la extracción de armas, lo que ayudó a los investigadores y aumentó la eficacia de los analistas.
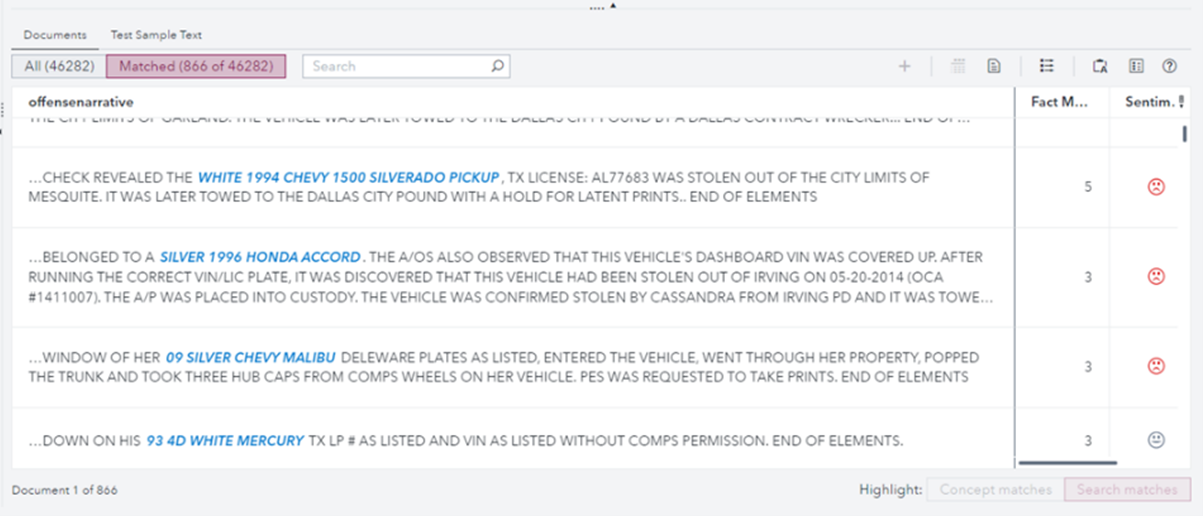
Se desarrollaron reglas adicionales en VTA para extraer los vehículos de la documentación que almacenaba la policía. Esta regla utilizaba una combinación de características de un vehículo, como el color, la marca, el modelo, el año, el tipo y los descriptores clave de un vehículo. Al observar las combinaciones de estas características, extrajimos muchos vehículos de la información de la que disponíamos y proporcionamos información adicional y útil al profundizar y observar los patrones en la colección de documentación policial disponible. En la figura 4 se muestran ejemplos de los vehículos identificados.
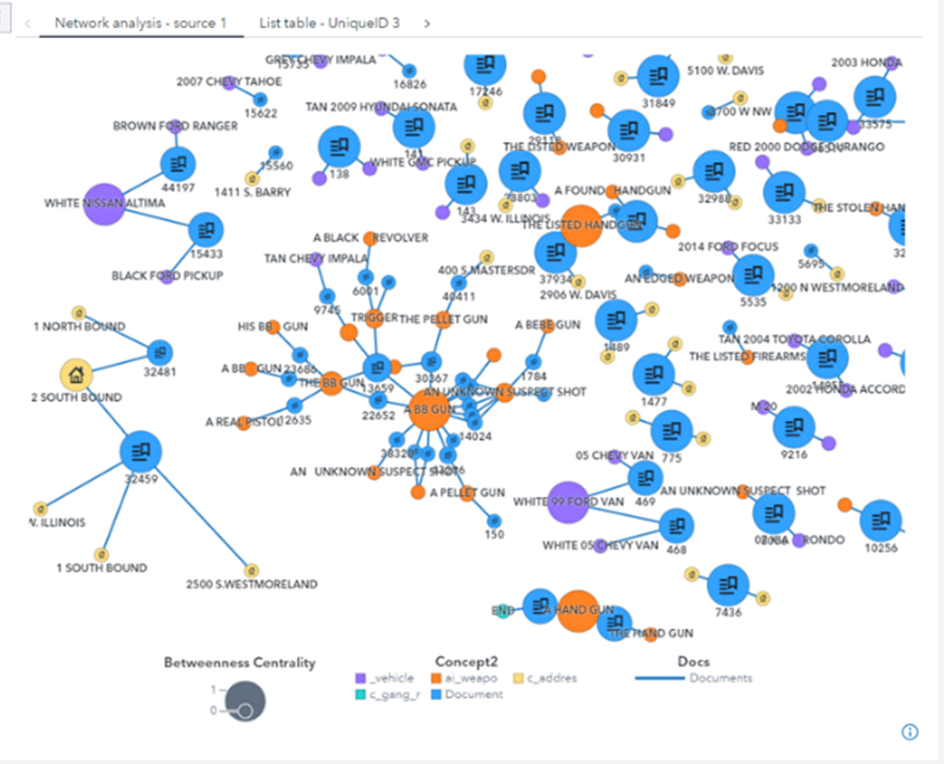
Muchos de los conceptos extraídos se muestran en el diagrama de red (Figura 5) que aparece a continuación en relación con los documentos fuente. Los nodos azules son los documentos de origen, los amarillos son direcciones y los naranjas son menciones de armas. Esta visualización permite a los usuarios examinar rápidamente coincidencias, tendencias y posibles modus operandi en los más de 40.000 documentos policiales. Muchos de las relaciones y coincidencias serían imposibles de detectar mediante una revisión manual sin la ayuda de la extracción de conceptos y las visualizaciones. En la Figura 5 se pueden ver numerosos ejemplos de tendencias potencialmente interesantes. Por ejemplo, podemos ver información sobre una furgoneta Chevy blanca de 2005. Esto podría indicar una tendencia para este vehículo y justifica un examen más detallado de la información de origen. Otro ejemplo es el examen de la frecuencia y las tendencias con las que se hace referencia a armas o direcciones específicas en los informes.
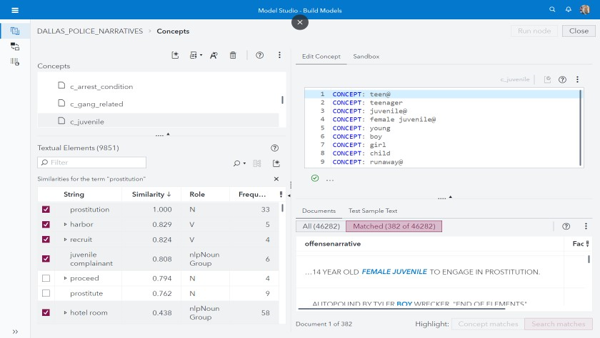
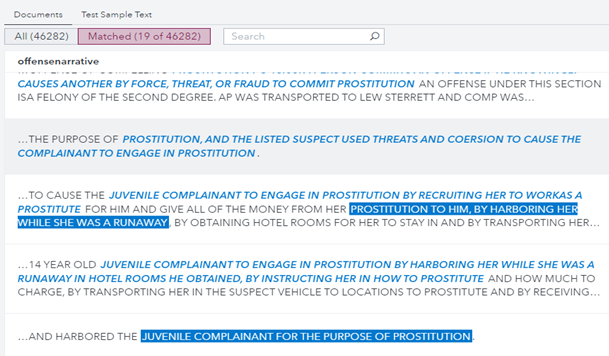
Las reglas relacionadas con la trata de seres humanos se desarrollaron utilizando IA y métodos estadísticos en SAS Visual Analytics para identificar patrones en torno a conceptos de interés ya conocidos. Por ejemplo, en la figura 6, al buscar términos similares a "prostitución" en el conjunto de información, identificamos inmediatamente términos relacionados con la trata, como "albergar", "reclutar" y, en particular, "menor denunciante".
A partir de aquí, utilizando métodos de IA y reglas adicionales relacionadas con las amenazas, la coacción, el chantaje y las fugas, pudimos señalar incidentes que ponían de relieve la trata de seres humanos directamente (como en la Figura 7) o destacaban situaciones de riesgo como la violencia física contra mujeres/adolescentes que podrían estar relacionadas con la trata de seres humanos directamente o podrían crear una situación de trata en el futuro.
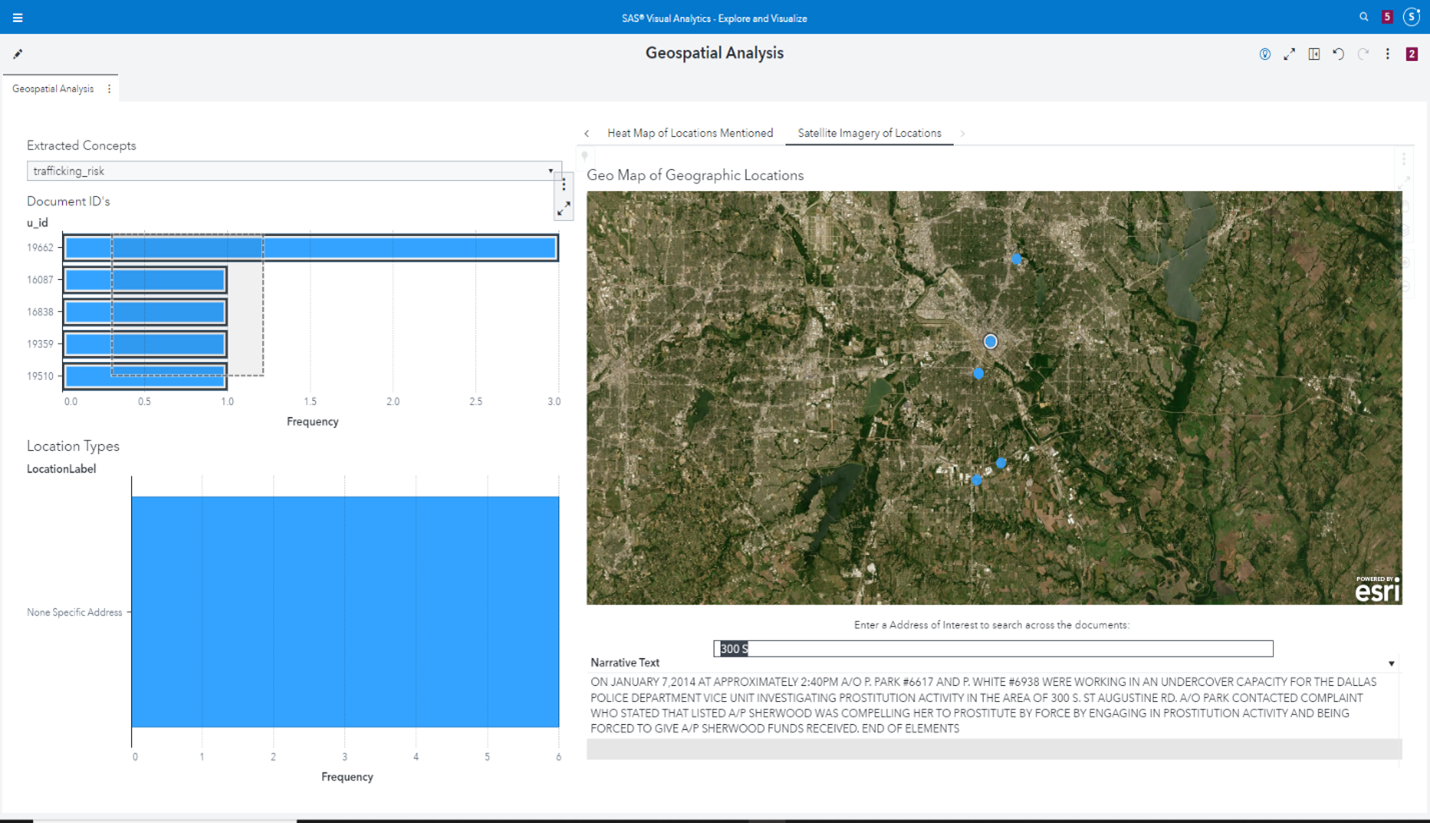
Juntando todo esto, pudimos utilizar los métodos geoespaciales mencionados anteriormente para obtener aquellos incidentes que implican trata de seres humanos o un riesgo de trata de seres humanos para ponerlos a disposición de la investigación como muestra la Figura 8. Se trata de un cuadro de mando intuitivo que un investigador o un agente de policía podría utilizar.
En resumen, nuestro objetivo era mostrar cómo, a partir de unos datos estructurados mínimos, aprovechamos las capacidades de análisis de texto para identificar patrones en la información que pudieran utilizarse de forma intuitiva. Aunque los departamentos de policía disponen de metadatos adicionales relacionados con estos incidentes, es posible que dichos metadatos sólo permitan identificar un delito primario, como un incidente de consumo de drogas, mientras que en la información textual puede haber indicios de una cuestión secundaria, como el riesgo de trata de seres humanos. Además, se podrían aplicar métodos similares a otras fuentes de datos textuales de la investigación, como las pistas o transcripciones de declaraciones o llamadas, y así ayudar a filtrar, clasificar y utilizar esta información para una acción policial rápida.
Para más información
- Accede a la documentación adicional sobre la escritura de reglas conceptuales y el análisis visual de textos.
- Consulta el libro electrónico Make Every Voice Heard with Natural Language Processing o accede al apartado Analítica visual de textos.
Este contenido está traducido y basado en el blogpost escrito por Kirk Swilley y Tom Sabo.
